Subproject
RoomKG Baselines
A neurosymbolic benchmark for temporal knowledge-graph memory under partial observability.

Overview
Turn partial observability into a benchmark for graph-structured long-term memory.
Authors: Taewoon Kim, Vincent Francois-Lavet, and Michael Cochez.
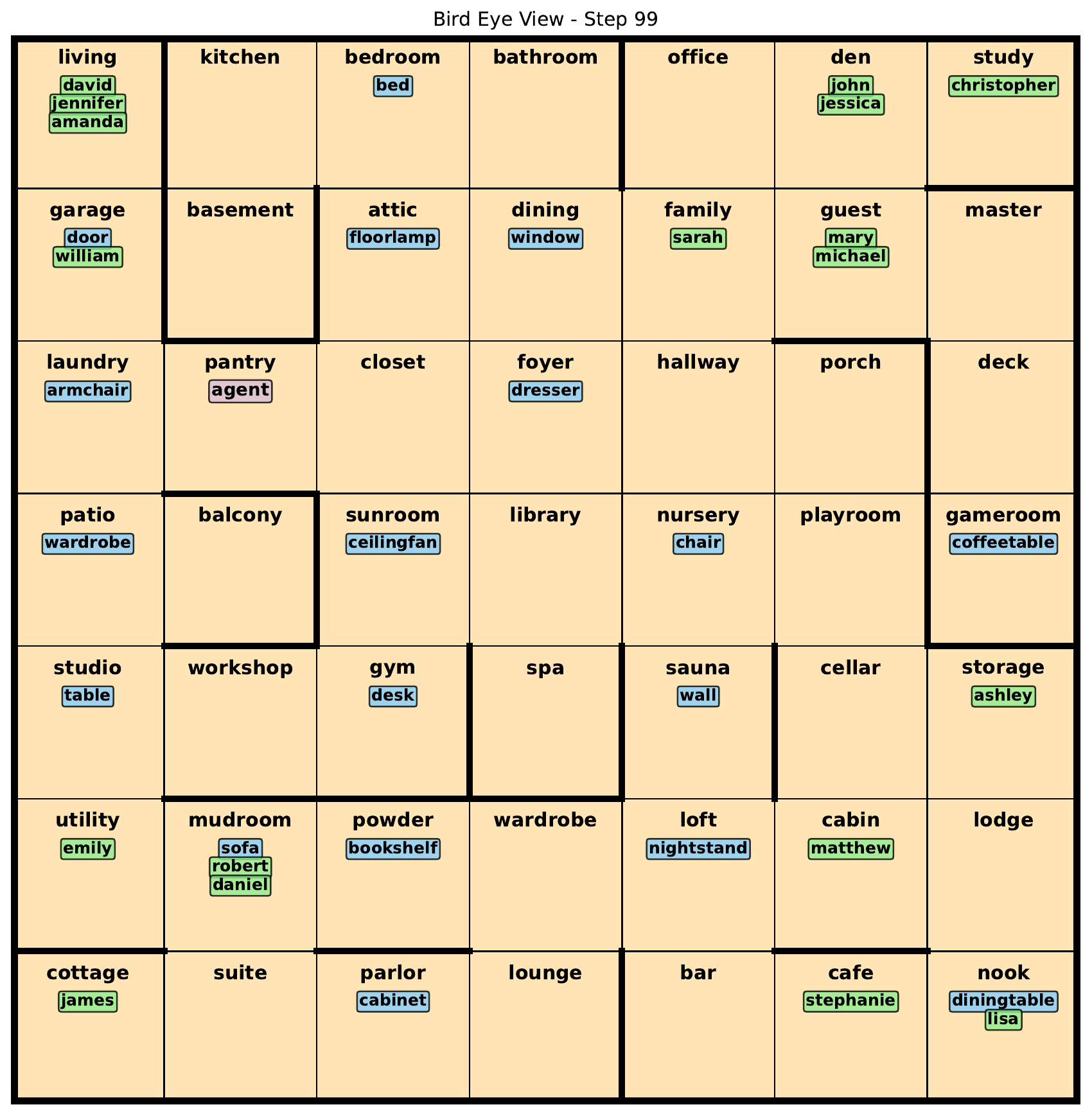
RoomKG Baselines turns long-term memory into the main object of study rather than a side effect of policy learning. The hidden world state is an RDF knowledge graph, observations are RDF triples over locally visible structure, and agents must answer object-location questions while navigating a changing environment under partial observability.
The benchmark builds on RoomEnv-v3, so the public RoomEnv repository is part of the contribution here too: these baselines are the agents, but the environment itself is the shared benchmark surface that makes the comparison meaningful and reproducible.
That shift makes the benchmark itself graph-native. Instead of asking whether one memory architecture happens to work inside one environment, the project aligns hidden state, observations, long-term memory, and evaluation around knowledge-graph structure so symbolic and neural approaches can be compared on the same controlled task.
We contribute a configurable RoomKG benchmark, a set of symbolic and neural baselines, and public benchmark artifacts for reproducible comparison. Read the full paper on arXiv.
Agents
Compare explicit symbolic memory against sequence-based neural baselines.
We evaluate four agents. Two symbolic agents store explicit graph structure: a plain KG agent keeps unannotated RDF triples, while a TKG agent stores RDF 1.2 annotated triples with temporal metadata such as when a fact was added, when it was last accessed, and how often it was recalled. Two neural baselines instead keep tokenized observation histories and learn question answering end to end with either an LSTM or a Transformer.
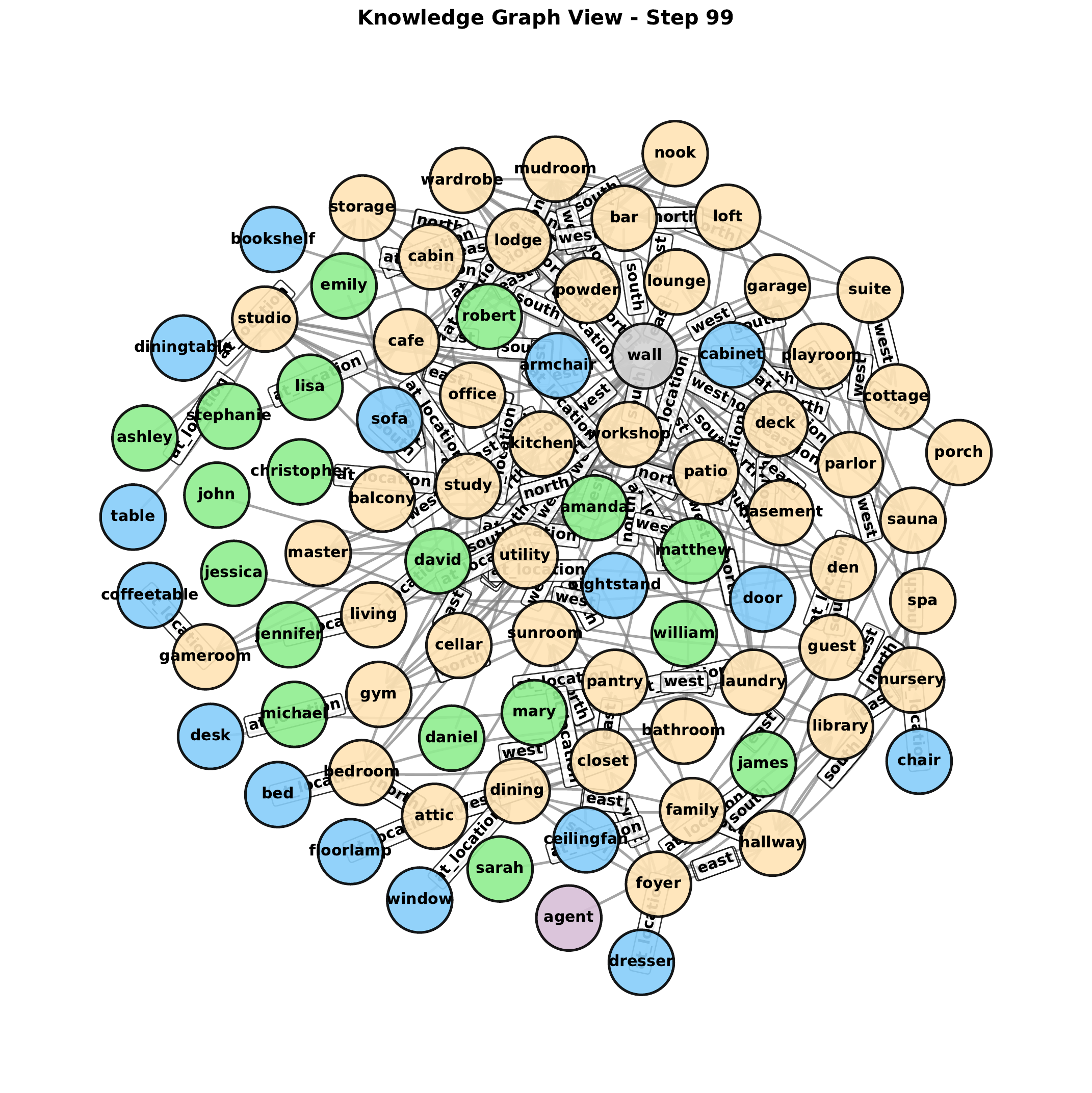
The symbolic memory used in the strongest agent is not just a set of triples. Each observed fact is stored as an annotated RDF-star triple, , together with the annotation fields , , and . That is the paper's key move: the memory is a temporal knowledge graph built from annotated triples rather than a plain bag of observations.
Those agent families face the same task but behave very differently. Symbolic agents answer questions through graph querying and graph-based exploration, while neural agents must jointly learn exploration and question answering through a single policy over longer and longer observation histories as memory capacity grows.
Those annotations induce concrete answer-selection rules, but they read better in words than as notation here. MRA means most recently added, MRU means most recently used, and MFU means most frequently used. When several triples match a query, the TKG agent can rank them by when they were added, when they were last accessed, or how often they have been recalled. That gives it recency- and usage-aware answer, exploration, and eviction behavior that the plain RDF agent simply does not have.
A key design choice is that all four agents share one benchmark and one evaluation surface. That makes RoomKG Baselines more than an implementation repo for one model: it is the comparative layer that shows what different memory representations gain or lose under the same partially observable environment.
Results
Temporal knowledge-graph memory outperforms the neural baselines on the same benchmark.
The main quantitative result is that symbolic agents begin to outperform neural agents once long-term memory becomes large enough to matter. At a capacity of 512, the best TKG variant reaches 45.64 test QA accuracy, while the best neural baseline reaches 11.2, a roughly four-fold difference under the same benchmark conditions.
At the environment level, the hidden state is an RDF graph , while the observation is only a local fragment . That partial-observability gap is exactly why long-term temporal memory matters in this benchmark.
The qualitative picture is consistent with that result. Symbolic agents keep exploring until they cover all 49 rooms and accumulate nearly complete internal maps, while the neural agents plateau much earlier and stop discovering new rooms. Temporal annotations give the TKG agent an additional advantage over the plain KG agent because recency and recall statistics make exploration, answering, and eviction more informative under a fixed memory budget.
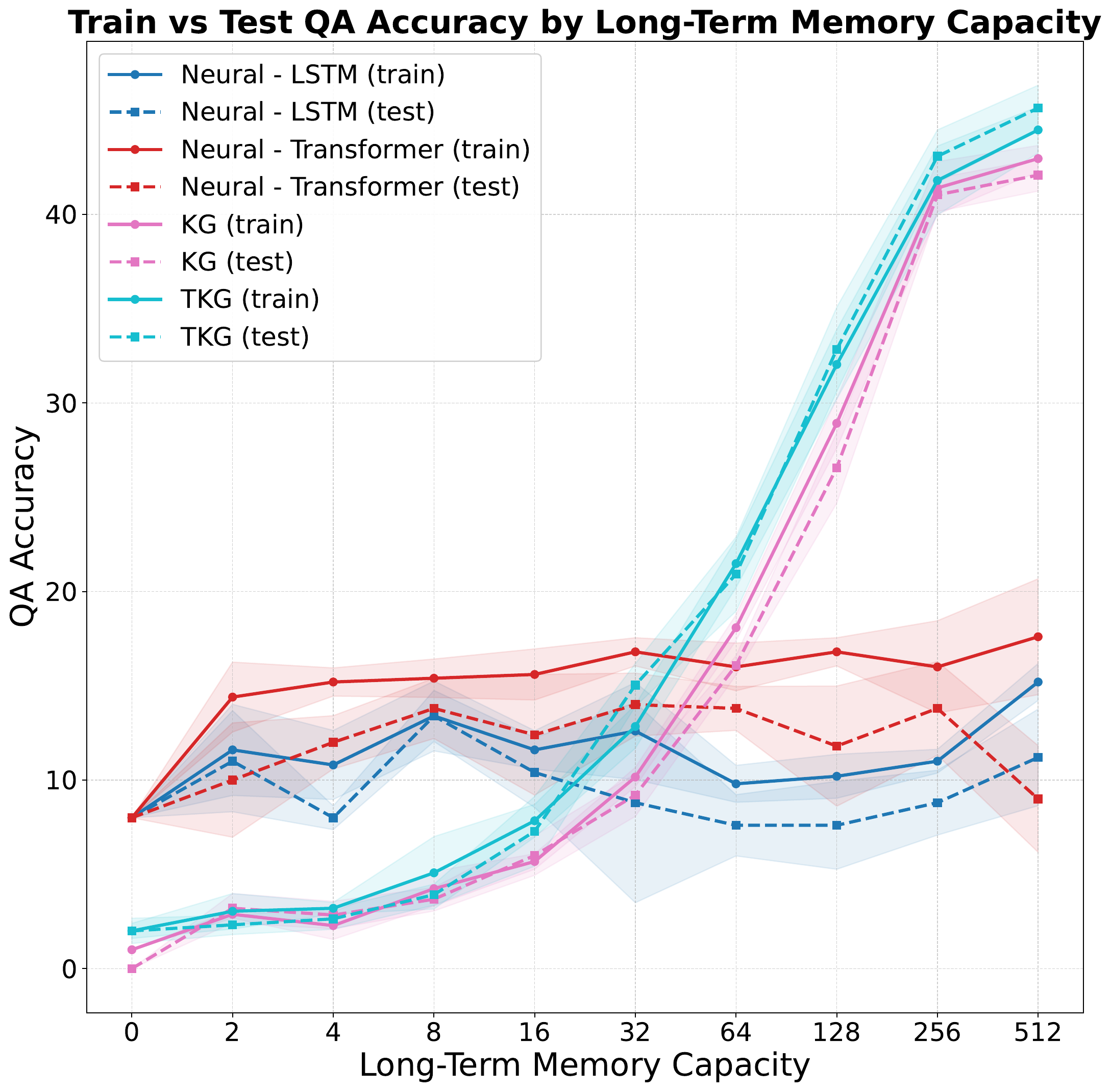
Train and test QA accuracy across long-term memory capacities show symbolic agents overtaking neural baselines once memory becomes large enough to support persistent reasoning.
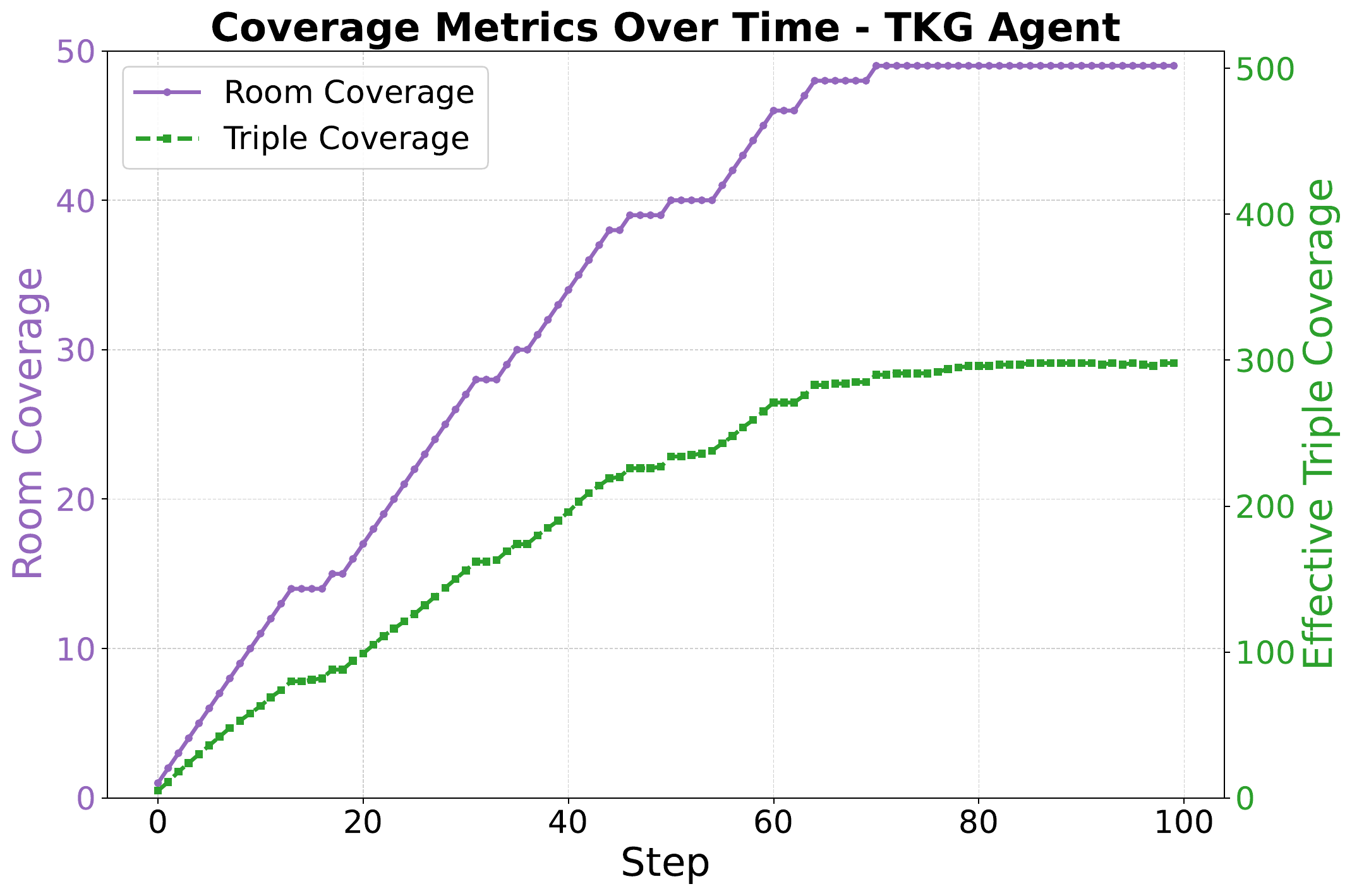
Coverage metrics for the TKG agent show that temporal symbolic memory supports sustained exploration and nearly complete triple coverage over an episode.
Takeaways
This project makes long-term memory explicit, inspectable, and benchmarkable.
RoomKG Baselines marks the point in the broader research line where long-term memory becomes a benchmark object in its own right. The hidden state is graph-structured, the observations are graph-structured, the symbolic memories are graph-structured, and the evaluation is designed to reveal whether an agent actually remembers over time rather than merely appearing to do so.
That gives the project a different role from the earlier memory papers. It is not only a new memory architecture or a stronger agent; it is the benchmark and baseline surface for comparing future symbolic, temporal, and neurosymbolic memory systems under shared conditions.
Resources
Paper and GitHub links.
Cite
Cite our paper.
@misc{kim2026temporalknowledgegraphmemorypartially,
title={Temporal Knowledge-Graph Memory in a Partially Observable Environment},
author={Taewoon Kim and Vincent François-Lavet and Michael Cochez},
year={2026},
eprint={2408.05861},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2408.05861},
}