About
From memory research to practical AI.
HumemAI started from research into human-like memory systems for AI and now focuses on turning that work into practical tools and products.
Overview
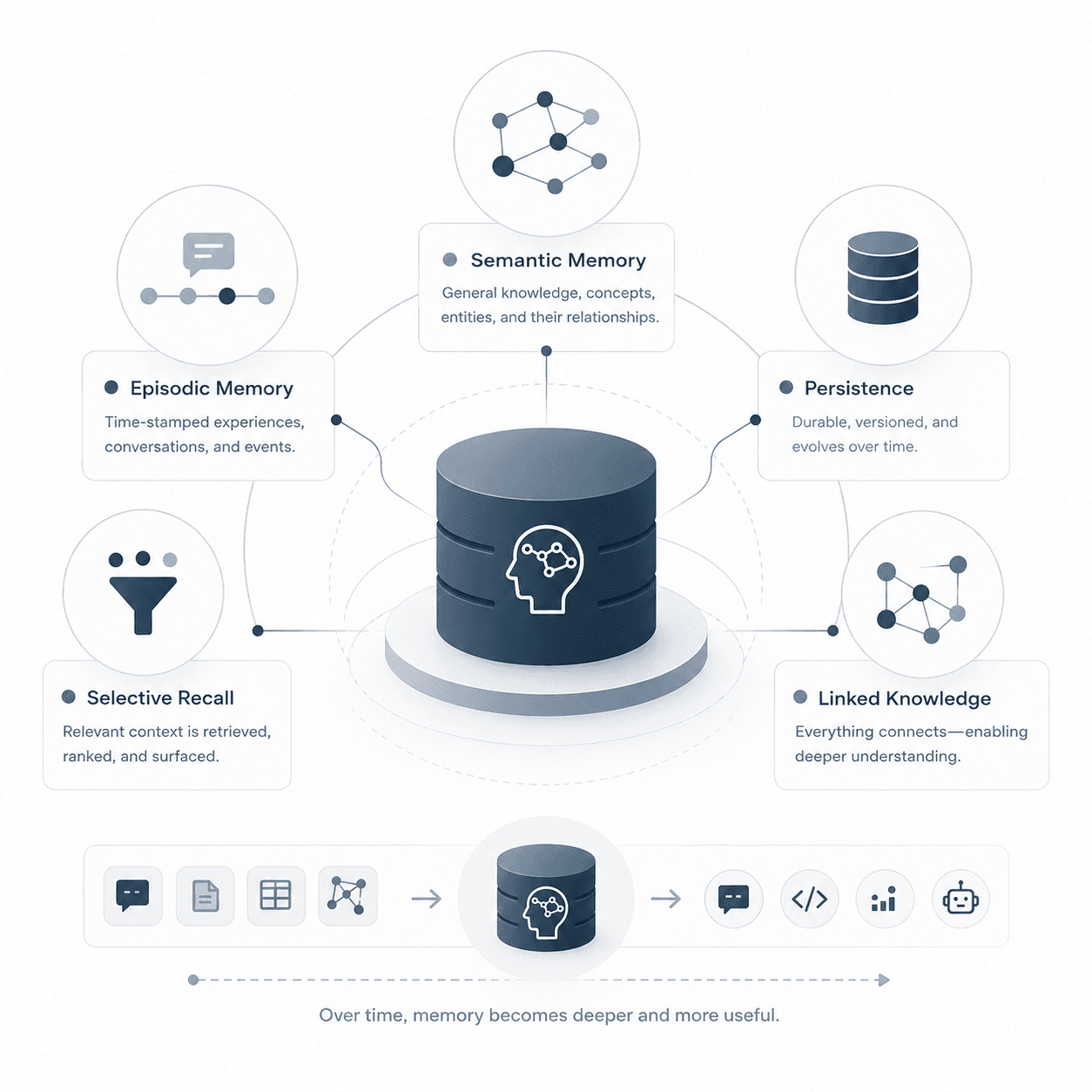
Memory should be a real system layer, not a prompt trick.
HumemAI is built around a straightforward idea: conversations and data are not the same thing.
Agentic systems need memory structures that stay structured, inspectable, and durable over time.
Origin
From research into usable systems.

HumemAI was founded by Taewoon Kim, an AI researcher and engineer working on agentic memory.
The company grows out of research on human-like memory systems and explicit memory architectures for AI, with a practical goal: turn those ideas into software that teams can use to build reliable agents.
Next