Subproject
KG Memory Transfer
A learned keep-drop transfer policy for long-term knowledge-graph memory under partial observability.

Overview
Turn short-term symbolic observations into a selective long-term memory problem.
Authors: Taewoon Kim, Vincent Francois-Lavet, and Michael Cochez.
KG Memory Transfer follows directly from RoomKG Baselines, but it asks a different question. Once an agent already has an explicit temporal knowledge-graph memory, the next problem is not only how to query that memory, but which newly observed symbolic facts should be transferred into it in the first place.
We treat consolidation as the main learning problem. Each locally observed RDF triple is a short-term candidate that can either be kept or dropped before long-term insertion. That keeps the memory contents explicit and inspectable while making transfer itself the object of study rather than a hidden systems detail.
Method
Learn a per-item keep-drop transfer policy instead of using a fixed rule.
We isolate transfer so the result can be attributed to consolidation rather than to many changing policies at once. Question answering, exploration, and forgetting stay fixed, while the learned policy decides only whether each short-term fact should be promoted into long-term temporal RDF memory.
The central formal step is to treat transfer as a variable-cardinality binary decision problem. If the current short-term memory contains candidate triples at step , then the transfer action space is
where means keep and means drop for one short-term item. That makes transfer an explicit per-item policy instead of a hidden side effect of a larger recurrent model.
That creates a non-standard control problem because the number of short-term candidates changes at every step. The solution is a shared-parameter per-item Q-learning design: score each candidate triple independently with keep-drop values, then learn those values through temporal-difference updates over matched short-term memories across steps. Because the short-term memories are RDF triples with annotations stored as a set rather than an ordered sequence, there is no canonical cross-step alignment. We therefore use randomized, order-agnostic pairings as the simplest matching strategy instead of fixed positional alignments.
The symbolic memory state then evolves as
where is the current symbolic memory state, is the next local observation, and is the keep-drop vector over the current short-term items. The update function applies short-term refresh, selective insertion into long-term memory, and the fixed eviction rule. The learned part is only the keep-drop vector .
To handle changing short-term set size, the network with parameters outputs one pair of Q-values per candidate item rather than one monolithic action score:
Here indexes the current short-term candidates, and each row contains the keep/drop values for one short-term triple. The shared parameters let one network score variable-length short-term sets without assuming a fixed action count.
The temporal-difference target used for the per-item transfer updates can be written more simply as
where indexes the -th sampled pair produced by the randomized matching procedure rather than the same persistent fact across consecutive steps, is the reward for the sampled transition, is the discount factor, is the terminal flag, is the next symbolic memory state, and is the target network. Because short-term memories are set-valued rather than inherently ordered, there is no natural one-to-one positional matching across consecutive steps. We therefore use randomized, order-agnostic matching as the simplest set-compatible way to form TD targets. The averaged per-match TD loss for one transition can be written as
where is the number of matched pairs used in that transition. This is what makes the keep-drop policy trainable even though short-term memory size changes from step to step.
The experiments focus on a controlled setting at long-term memory capacity 128. We evaluate symbolic temporal-RDF baselines such as Always-Transfer, Novel-Only, and Random-Transfer (), compare them against end-to-end LSTM and Transformer baselines, and then study learned DQN temporal-RDF transfer policies with GCN, R-GCN, and StarE-GNN encoders under local and global transfer variants.
Results
A local learned transfer policy beats both symbolic heuristics and neural baselines.
At long-term memory capacity 128, the strongest configuration is the DQN temporal-RDF agent with a GCN encoder and Local-STM transfer policy. It reaches 38.920 test QA accuracy, improving over the strongest symbolic baseline, Novel-Only at 31.960, and staying far ahead of the end-to-end neural baselines, where the Transformer reaches 11.800 and the LSTM 7.600.
The ablation pattern matters as much as the best score. With the same GCN encoder, the Local-STM transfer policy outperforms Local-Full, Global-Full, and Global-STM. In this regime, a lightweight per-item policy over short-term input works better than pooled global transfer decisions, which suggests that explicit local transfer is the right inductive bias for this memory-constrained symbolic setting.
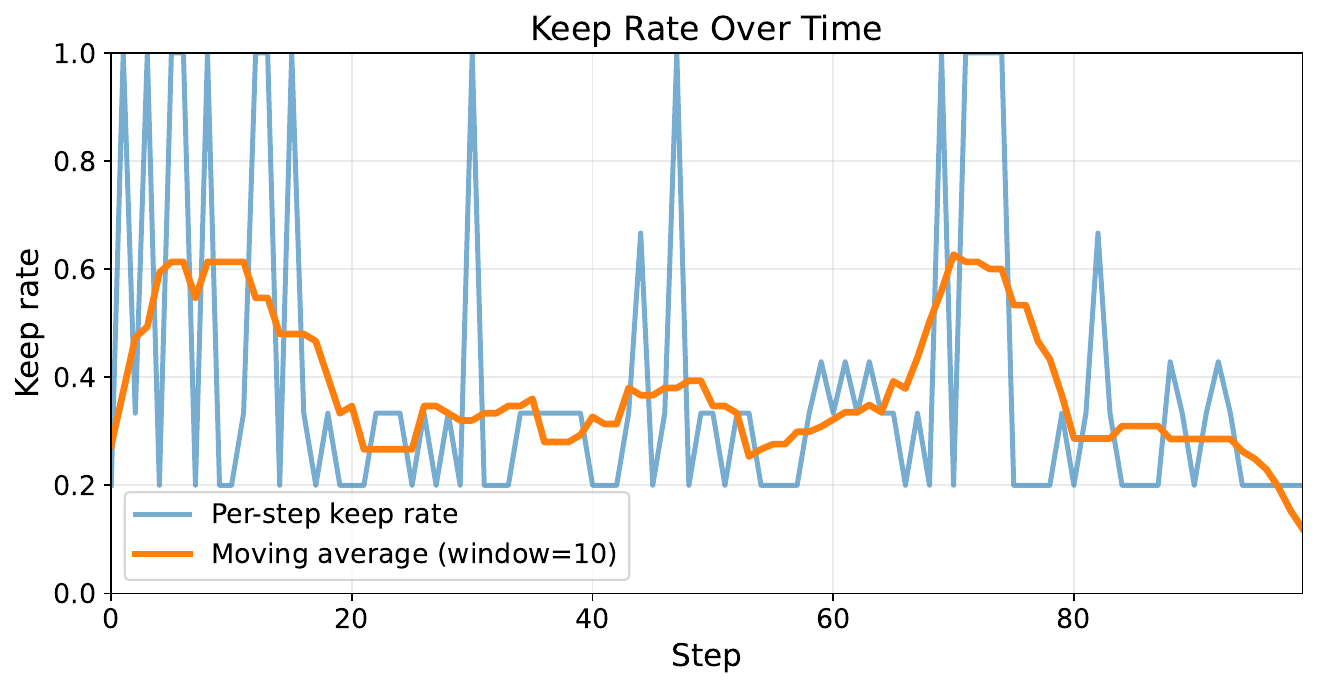
The keep rate changes over time rather than behaving like a fixed filter, which shows that transfer is adaptive to local memory state.
Behavior
The learned policy stays selective in ways that match navigation and question answering.
A key strength of this work is that the learned transfer behavior remains inspectable. Across 560 held-out transfer decisions over 100 steps, the policy keeps 224 items and drops 336. That is an overall keep rate of 0.40, but the mean rate is less important than the selectivity pattern.
Three patterns stand out. First, the policy almost always keeps the agent's own location signal, preserving 98 times out of 100. Second, it strongly keeps question-relevant object-location facts, preserving them 58 times while dropping them only 2 times in the held-out query set. Third, it drops many directional room-link facts, suggesting that a large share of local map-link observations are lower-value than self-localization and answer-relevant object memory.
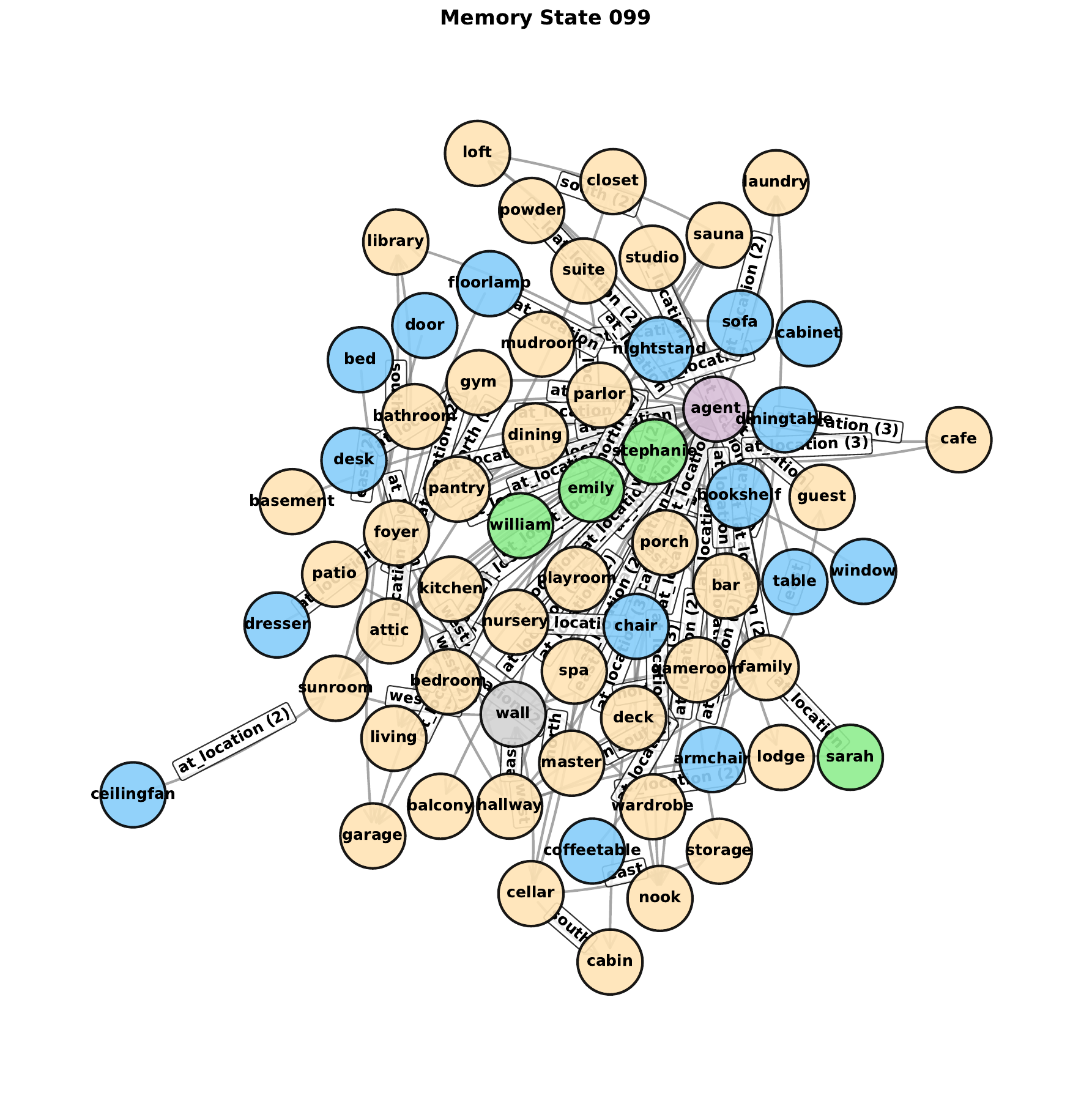
Because the transfer policy acts on explicit triples, the resulting long-term memory can be inspected directly as symbolic graph structure.
Takeaways
Explicit keep-drop transfer decisions improve graph-structured long-term memory.
We study one specific mechanism inside partially observable temporal knowledge-graph memory: short-term-to-long-term transfer. Instead of relying on fixed symbolic heuristics or opaque latent-state updates, we learn explicit keep-drop decisions for each observed triple under memory constraints while keeping those decisions auditable at fact level.
The central result is that this explicit transfer policy improves question answering over both symbolic and neural baselines in the controlled RoomKG setting at memory capacity 128, while also revealing why it works: the agent preferentially retains navigation-relevant and query-relevant facts and drops many lower-value candidates.
Resources
Paper, code, and project links.
Cite
Cite our paper.
@misc{kim2026shorttermtolongtermmemorytransferknowledge,
title={Short-Term-to-Long-Term Memory Transfer for Knowledge Graphs under Partial Observability},
author={Taewoon Kim and Vincent François-Lavet and Michael Cochez},
year={2026},
eprint={2605.22142},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2605.22142},
}