Table of Contents
- Table of Contents
- Motivation
- The human memory system
- Incorporating the human memory system in AI
- Science and engineering of HumemAI
- Conclusion
- Cite this article
- References

Motivation
I’ve always been fascinated with intelligent machines. They have the power to augment our lives. They become more powerful if we can talk to them in a natural language. This became reality with ChatGPT (OpenAI 2022). ChatGPT is by no means perfect. Everytime you start a new conversation, it starts from scratch, meaning that it does not remember who you are. OpenAI is trying to tackle this problem with its “memory” (OpenAI 2024), which seems to be another prompt engineering based feature. A more effective strategy would be to prioritize the development of an AI with its memory capabilities as the foundational element. That’s why I started my project “A Machine With Human-Like Memory Systems”, a.k.a. HumemAI https://humem.ai/.
The human memory system
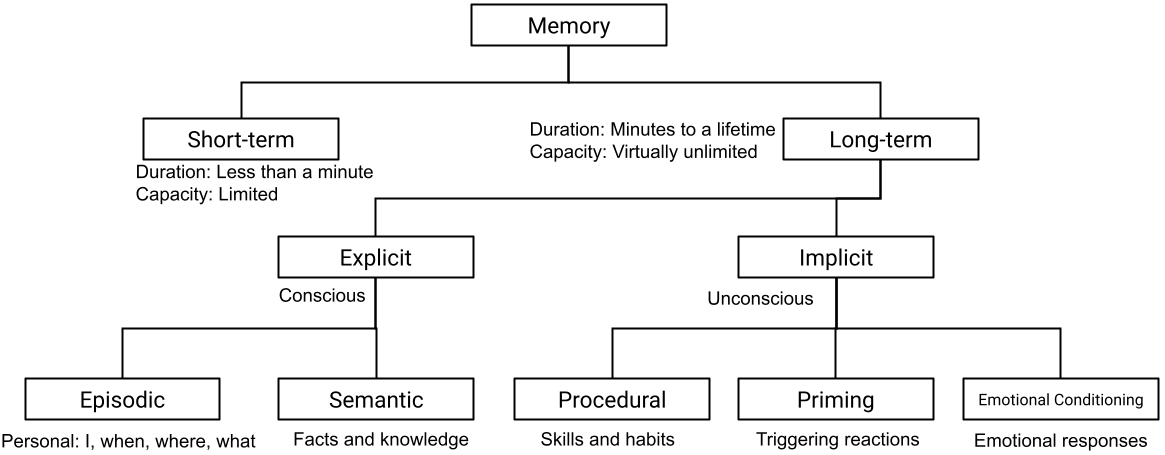
Let’s first try to understand how human memory systems work. Above is the human memory hierarchy. At the heart of this system are two critical components: short-term (or working) memory and long-term memory, each playing unique roles in the cognition process.
Short-term memory or working memory
This stage temporarily holds and processes a limited amount of information, typically for about 20 to 30 seconds. It’s not just a passive storage space but an active workshop where information is manipulated for various cognitive tasks, such as problem-solving, language comprehension, and planning. Working memory is where conscious thought primarily occurs, integrating new sensory inputs with information retrieved from long-term memory to make sense of the world around us.
Long-term memory
Information that is deemed important or is repeatedly rehearsed in short-term memory can be transferred to long-term memory, where it can remain for days, years, or even a lifetime. Long-term memory is vast and can store a huge quantity of information. It is divided into explicit (or declarative) memory, which includes memories that can be consciously recalled, such as facts and events, and implicit (or non-declarative) memory, for the skills and habits we’ve acquired, the phenomena of priming, and our emotional responses. Priming is an aspect of implicit memory that deals with the unconscious influence of an earlier presented stimulus on the response to a later stimulus. Emotional conditioning is another facet of implicit memory, involving the learning of emotional responses to certain stimuli. Through experiences, certain neutral stimuli can become associated with emotional responses, shaping our preferences, fears, and even our interpersonal relationships.
Sensory memory
What’s not included in the above hierarchy is sensory memory (information). This memory is a bit different from the others. Sensory memory acts as the initial stage in our memory system, capturing all the information from our environment through our senses. It quickly filters through this vast amount of data to decide what is important enough to pass on to our short-term memory. This process is like a brief moment of consideration before some of this sensory information is selected for further attention and use. Therefore, sensory memory is directly linked to short-term memory as it serves as the gateway, ensuring that only the most relevant information makes it to the next stage where we can consciously work with it.
Incorporating the human memory system in AI
Graphs as memories
Graphs are well studied in computer science. When data is represented as a graph, we can take advantage of all the useful computer science methods on them. For example, Google Maps use graphs to represent roads, intersections, and locations as nodes, and the distances or travel times between them as edges. This allows the application to use graph algorithms, such as Dijkstra’s or A* search algorithm, to efficiently find the shortest path or the fastest route between two points.
So in my project HumemAI, I model short-term and long-term memories as graphs. More specifically, I use a Knowledge Graph (Hogan, E. et al. 2020) to represent them. In knowledge graphs, nodes represent entities, concepts, or events, while edges represent relationships or associations between these nodes. These relationships can vary widely, from causal links, e.g., “leads to”, “causes”, associative connections, e.g., “related to”, “associated with”, to hierarchical relationships, e.g., “is a type of”, “is part of”. Edges provide the structure of the knowledge graph, defining how individual pieces of information are interconnected. Knowledge graphs are used in many applications. For example, Google uses knowledge graphs to enhance its search engine, providing not just links to web pages but also structured and detailed information relevant to the user’s query. Below is an example of a knowledge graph that I obtained from a blog post (Pavlik, V. 2023).

Representing human-like memory systems with knowledge graphs comes with a lot of benefits. First, we can take advantage of the open knowledge graphs out there that everyone can use it for free, e.g., DBpedia, Wikidata, and YAGO. These vast, publicly available resources provide a rich foundation of structured knowledge that can be directly incorporated into our memory systems. By leveraging these open knowledge graphs, we can significantly reduce the time and resources needed for data collection and curation, allowing us to focus on developing more sophisticated algorithms and functionalities. Furthermore, these knowledge graphs are constantly updated and expanded by a global community of contributors, ensuring that the information our system relies on is both current and comprehensive. This aspect is particularly valuable for mimicking human memory, which is dynamic and continually evolving. Integrating these open resources enables our memory systems to not only access a wide array of facts and relationships, but also to stay updated with new knowledge, mirroring the learning process in humans. Additionally, the structured format of knowledge graphs facilitates more accurate and context-aware information retrieval, enhancing the system’s ability to understand and interpret complex queries or tasks in a manner similar to human cognitive processes. In HumemAI, I use these public knowledge graphs as semantic memory, as it has to do with factual knowledge, rather than personal.
Episodic memory, on the other hand, is built by the agent itself through its interactions within the environment, making it personal to the agent based on its unique experiences. Cognitive neuroscientist Endel Tulving (Tulving, E. 1972) outlined that the core components of an episodic memory system include the aspects of “I” (the agent itself), “when” (the timing of the event), “where” (the location or digital context), and “what” (the nature of the interaction). For example, if an agent assists a user in finding specific information, it would encode this interaction by noting itself as the participant, the time and digital location of the event, and the details of the user’s request and the provided answer. This method of encoding allows the agent to use past experiences to improve future interactions, adapting to user preferences and providing personalized responses. An agent could, for instance, anticipate a user’s daily request for weather updates and proactively provide this information, demonstrating learning and adaptation similar to human behavior. We can include this information as key-value pairs of properties that condition nodes and edges.
Episodic memory is tightly connected to emotion. For example, emotionally charged events are often more vividly remembered and more easily recalled than neutral events. This is because the emotional content of an experience can enhance the encoding and consolidation of that memory, making it more resilient to forgetting. In humans, this means that memories of significant life events, whether joyous or traumatic, tend to be more detailed and lasting. Similarly, when designing artificial intelligence systems with episodic memory capabilities, incorporating an emotional component could improve the system’s ability to remember and learn from interactions that have a strong emotional context. This could involve analyzing the sentiment of interactions or recognizing the emotional states of users to better encode and recall these events, thereby making the AI’s interactions more personalized and effective. In HumemAI, emotion will also be part of the episodic memory graph.
Procedural and priming are not considered at this moment. Procedural might be considered in the future when the AI becomes embodied. In general, I find it hard to model implicit memory with a graph. Emotional conditioning is an exception, since it’s tightly connected to episodic memory.
Knowledge graphs can also be saved as a (graph) database. This means that we can use all the power of a database. This allows for efficient querying, updating, and management of data. This means that complex relationships between entities can be explored and analyzed quickly, thanks to the database’s ability to perform graph-specific operations like traversals and pathfinding. Furthermore, graph databases are optimized for handling interconnected data, which significantly improves performance and scalability for applications relying on rich relational data, enabling real-time insights and responses in dynamic environments. This will be exceptionally useful when the agent’s memory gets huge and if it has to update and query its memories.
So far, we’ve talked about the symbolic aspect of graphs, where nodes represent entities or concepts and edges represent the relationships or connections between these entities. This symbolic representation is crucial for enabling logical reasoning and inference over the represented knowledge. By structuring data in this way, we can apply logical operations and rules to deduce new information or evaluate the truth of specific statements within the graph.
Symbolic AI gets more powerful when it meets neural networks from deep learning. Machine learning has been studying graphs for a while, especially with the advent of Graph Neural Networks (GNNs), which are a perfect example of the fusion between symbolic AI and deep learning. This combination leverages the structured, symbolic representation of data in graphs with the adaptive learning capabilities of neural networks. GNNs can effectively capture the complex patterns within the graph data, learning to encode both the properties of nodes and the relationships between them. This enables more nuanced understanding and processing of graph-based data, allowing for tasks such as node classification, link prediction, and graph classification to be performed with high accuracy. Please read “A Boxology of Design Patterns for Hybrid Learning and Reasoning Systems” (Harmelen, F. et al. 2019), if you want to know more about this.
Raw input data in deep learning as sensory information
There are many sensory modalities that humans can sense, e.g., smell, haptic, acoustic, visual, etc. However, not all of them are useful if the machines can’t process them. So in this project, we’ll only consider the modalities that the machines can process. More specifically, we care about the ones that deep learning can handle. Currently, nothing beats deep learning when it comes to approximating a funtion whose input modalities are both human and machine understandable, e.g., text, audio, image, video, time-series, table, etc.
In HumemAI, these data will be “encoded” as short-term memory. I’m not talking about something like JPEG here. What I mean is that they will be encoded as a knowledge graph and be stored in the agent’s short-term memory system. Below is an example.

Both the entities, i.e., Male, Taewoon, Phone, and Living room, and relations, i.e., subclass of, holds, and located at, can have key-value properties, i.e., {age: 34} and {timestamp: 8-Mar-2024}. This makes it easier not only to filter things out, but also to modify the values if there are changes, e.g., Taewoon turns 35.
As with short-term memory of humans, the short-term memory won’t stay for so long. Therefore, the agent has to decide if it should be stored in the long-term memory or not.
Essential skills that the agent should learn
Memory encoding
This is essentially transforming raw input as a graph. As mentioned, it’s very likely that deep learning will handle this. The difficulty depends on the type of modality.
Memory storage (management)
This skill is about the movement of the memories in short-term and long-term memories. The agent should decide what part of the short-term memory should be saved in the long-term memory. Potentially, it should also decide what to do with its long-term memories, e.g., removing old ones.
Memory retrieval
As the agent interacts with the environment, it has to retrieve memories from its long-term memory to solve tasks, e.g., retrieving a relevant memory to answer a given question.
Memory decoding
According to Endel Tulving, when humans recall (retrieve) an episodic memory, we relive the moment. For example, if I recall what I did on my 30th birthday, I regenerate the sensory information, e.g., visual image, of that moment. Since I restricted the memory encoding to only handle the modalities that can be processed by deep learning, memory decoding will also handle those modalities.
Emotion
Our agent is empathetic. Every episodic memory of theirs is attached with one of the seven major emotions, i.e., neutral, joy, surprise, anger, sadness, disgust, and fear. This is what it felt at that moment. This will affect its memory retrieval skill, as memories with similar emotion will be more likely to be retrieved, according to emotional conditioning theory.
Exploration (curiosity)
Just like the Mars Curiosity rover, our agent is also curious. It likes to explore the world and have new memories. Learning this skill can be encouraged with something like entropy maximiation objective.
Science and engineering of HumemAI
There are a lot of science and engineering involved in the project of HumemAI. Therefore, I’ve broken it down into several stages so that we can divide and conquer. There is no perfect definition of “done” of each stage. It’s likely that all the stages are continuously and repeatedly visited and improved.
Stage 1: Learning the essential skills
Learning all of them at once is very difficult. Therefore, I’ll try to tackle them one by one. Also, I’ll experiment in a small environment first and then gradually increase the size of it. One more thing to mention is that this stage is my PhD thesis, although I couldn’t tackle all of them during the time.
- In order for the agent to be empathetic, it should first learn how to feel the emotion of humans. In the work “EmoBERTa: Speaker-Aware Emotion Recognition in Conversation with RoBERTa” (Kim, T. et al. 2021), we trained a RoBERTa (Liu, Y. et al. 2019) based classifier to classify a speaker’s emotion. By simply prepending speaker names to utterances and inserting separation tokens between the utterances in a dialogue, EmoBERTa can learn intra- and inter- speaker states and context to predict the emotion of a current speaker, in an end-to-end manner.
- In the work “A Machine With Human-Like Memory Systems” (Kim, T. et al. 2022), we replicated the properties of the short-term, long-term (episodic and semantic) memory systems, and simulated the memory storage and retrieval skills. Here we made a toy OpenAI Gym environment. Just as we humans do with our brain, we included the temporal aspect to the episodic memory system and the strength aspect to the semantic memory system.
- It’s not always worthwhile to store all short-term memories into a long-term memory system. If we humans do it, our brain will explode from too much information. In the paper “A Machine with Short-Term, Episodic, and Semantic Memory Systems” (Kim, T. et al. 2023), we let a reinforcement learning (RL) agent learn the memory management policy, by maximizing the return (discounted sum of rewards). The three actions are (1) forget it completely, (2) move it to the episodic part of the long-term memory system, or (3) move it to the semantic part of the long-term memory system.
- Agents that explore more than the others will definitely have more interesting memories stored in their brain than the agents that don’t. In this work, we encourage the RL agent to explore by asking questions about the object locations in random rooms. The more rooms the agent explores, the more likely that it can answer the questions. This work is currently under review.
- We humans have a good overview of the memories in the short-term memory system. We don’t have to consciously go through them one by one to understand how many short-term memories are stored in the buffer. In this work, we take advantage of a GNN so that the agent can have a similar level of awareness and efficiency in processing short-term memories. This work is currently a work in progress.
- Encoding an image into a short-term memory is a challenging problem. I have some ideas, but not so clear yet. Let me know if you have ideas on this.
- Encoding a natural language text into a short-term memory is a bit more straightforward than an image, since both natural language text and short-term memories have string values. There are probably various ways to do this, but I haven’t got into any of them yet.
- Encoding an audio into a short-term memory can be done by running a speech recognition model and then do the encoding of a natural language text into a short-term memory. This method, however, will lose some meaningful acoustic information, such as, the tone, pitch, and emotional nuance of the speaker’s voice, which can carry significant information beyond the words themselves.
- Encoding a video into a short-term memory might be as “simple” as processing a sequence of frames one by one. But probably not! A video is more than just a stack of images.
- Memory decoding, in the context of HumemAI, is the reverse of memory encoding. That is, this is a skill that turns a knowledge graph into text, image, audio, or a video. This is probably very challenging, but we have seen some remarkable decoders lately, e.g., diffusion models, LLMs with Transformer decoders, etc., that can generate very nice images and texts. The challenge in HumemAI is to condition them with a knowledge graph. LLM based agents are getting more attention. See this blog post “LLM Powered Autonomous Agents” (Weng, L. 2023) for more information.
- Symbolic memory retrieval can fail if there are no exact matches of memories. However, we don’t always have to retrieve the exact “correct” memory from our brain. We can also retrieve something similar that can help us solve a given task. This is how deep neural networks can help us. The generalization and approximation properties of an artificial neural network will definitely be helpful.
- Learning more than one skill at once is very challenging. From the mathematical point of view, this is optimizing more than one thing at once, which makes the objective is non-stationary. However, learning multiple skills simultaneously can also lead to greater adaptability and cognitive flexibility. Multitasking in skill acquisition forces the brain to navigate and integrate diverse sets of knowledge and skills, enhancing problem-solving abilities and creativity. This approach aligns with the concept of transfer learning in cognitive science, where learning in one area can positively influence performance in another unrelated area.
Stage 2: Scaling things up
Scaling things up in general is a very big challenge in computer science / engineering. It’s very impressive how these big LLMs can have hundreds of billion parameters. If there are too many memories loaded, RAM might not have enough capacity to handle them. In this stage, graph databases will definitely be helpful so that some of them can just stay in disk. Sampling might be useful here too. I can sample a subset of the agent’s long-term memories. Of course the challenge is how to sample them.
Stage 3: Production ready in the digital world
This stage is production ready phase. Humans will actually interact with the machine, and it’ll use all the mentioned policies. This will involve a lot of software engineering. Many things to be considered here, e.g., cloud, front-end (web based? Android app?). Input / output modalities should be considered. The easiest is when both input and output are natural language. I’ll probably start with that. But if it can extend to audio and vision, it’ll be amazing.
In the beginning, I’ll have the humans interact with the agent by solving some kind of simple problem together. It’s probably easier when there is an objective, so that the both sides don’t end up talking about random stuff. After assessing the human-machine interactions, I’ll have a better idea what humans want from HumemAI agent, or even what the agent wants from humans. Considering the opinions from the both sides, I’ll add more collaborative tasks and conversation topics.
Stage 4: Production ready in the real world
This is the last stage. Now things are ready to be deployed to the real physical world. An embodied agent can have different forms, from a 3D-printed toy robot to a full humanoid robot. Of course, I’ll start from something simple. Navigation can include procedural (implicit) memory. This type of memory is very different from explicit memory. It probably doesn’t make sense to model procedural memory with a graph anymore.
Conclusion
In conclusion, the journey of developing HumemAI, a machine with human-like memory systems, represents a groundbreaking leap in the realm of artificial intelligence. By intricately weaving the complexities of human memory—encompassing short-term, long-term, and sensory memories—into the fabric of AI through the use of knowledge graphs and deep learning, we have embarked on a path that significantly narrows the gap between human cognition and machine intelligence.
The project’s meticulous design, which spans from the foundational representation of memories as graphs to the advanced integration of emotional and exploratory capabilities, showcases the potential for AI systems to not only store and retrieve vast amounts of information but also to understand, interpret, and generate human-like responses in a dynamic world. This endeavor has not only shed light on the potential for AI to mimic human memory but has also underscored the importance of a multidisciplinary approach that bridges cognitive science, computer science, and engineering.
Through the phased development strategy—from mastering essential skills in controlled environments to scaling up for real-world interactions—HumemAI promises to revolutionize how machines learn, adapt, and interact within their environments. The final goal of deploying these AI systems in the physical world as embodied agents will not only expand their utility and applicability but also pave the way for more natural, intuitive human-machine collaborations.
The implications of this work are vast, with potential applications across education, healthcare, customer service, and beyond, offering personalized, empathetic, and efficient interactions. As we continue to refine and enhance HumemAI, it remains a testament to the power of interdisciplinary research and the boundless possibilities of AI when modeled after the intricate workings of the human mind.
Cite this article
@article{kim2024humemai,
title = "A Machine With Human-Like Memory Systems",
author = "Kim, Taewoon",
journal = "https://humem.ai",
year = "2024",
month = "Mar",
url = "https://humem.ai/2024-03-01-design-humemai/"
}
References
[1] OpenAI. 2022. Introducing ChatGPT
[2] OpenAI. 2024. Memory and new controls for ChatGPT
[3] Hogan, E. et al. 2020. Knowledge Graphs
[4] Pavlik, V. 2023 What Is the Google Knowledge Graph & How Does It Work?
[5] Tulving, E. 1972. Episodic and semantic memory
[6] Harmelen, F. et al. 2019. A Boxology of Design Patterns for Hybrid Learning and Reasoning Systems
[7] Kim, T. et al. 2021. EmoBERTa: Speaker-Aware Emotion Recognition in Conversation with RoBERTa
[8] Liu, Y. et al. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach
[9] Kim, T. et al. 2022. A Machine With Human-Like Memory Systems
[10] Kim, T. et al. 2023. A Machine with Short-Term, Episodic, and Semantic Memory Systems
[11] Weng, L. 2023. LLM-powered Autonomous Agents